关键词:
定理自动证明
流程图
大语言模型
专家系统
摘要:
数学问题的自动求解是数学和人工智能共同关注的重要研究领域。近些年,深度学习的快速发展为数学问题的自动求解提供了新的解决方案。但是,在处理图文结合问题和形式化语言下的定理自动证明问题时,深度学习还面临着巨大的挑战。本文针对高中数学难度的流程图求解问题和不等式证明问题,开发自动求解算法。研究的内容主要包括以下三个方面:
(1)基于交互式定理证明器Lean,设计了一种结合深度学习与专家知识的自动定理证明系统(a proving system integrating Deep Learning and Expert Rules,DLER-1),来解决不等式的证明问题。该系统由两个推理器、一个验证器和一个符号计算器组成。基于深度学习的推理器模拟人类的直观推理,基于专家知识的推理器模拟人类的逻辑推理。验证器判断推理策略的有效性,并返回新的证明目标。符号计算器化简表达式,优化推理器的性能。通过不同模块的协同工作,提升自动证明的成功率。在测试集中,DLER-1达到了59.7%的正确率,远高于GPT-4的8.10%正确率。
(2)在不等式证明领域,设计了借助非形式化证明提升形式化证明的研究框架,提出了三阶段的自动定理证明系统DLER-2。首先,在Python环境中导出自然语言形式的证明草稿。进而,将这些证明草稿通过正则表达式处理转化为Lean语言中的关键证明步骤。最后,以关键证明步骤提示GPT-4,完成Lean语言下的完整证明。在测试集中,DLER-2解题思路的正确率可以达到80.0%,相比于仅利用GPT-4的正确率取得了显著提升。
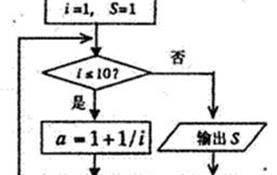
(3)设计了一种集成自然语言理解、图形结构理解和自动编程的流程图自动求解器(Automated Solver for Flow Chart,AS-FC)。AS-FC利用图形和文本的综合理解模块、图像-文本融合模块和自动编程模块,自动建立Python代码实现流程图求解。在高中水平的流程图问题数据集上,AS-FC的准确率达到85.2%,远优于目前主流的大语言模型GPT-4V。
 欢迎来到三峡大学图书馆!
欢迎来到三峡大学图书馆!
 详细信息
详细信息

