 欢迎来到三峡大学图书馆!
欢迎来到三峡大学图书馆!
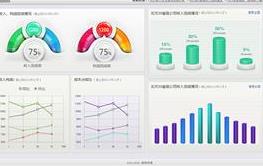
限定内容
主题
- 48,796 篇 数据处理
- 5,313 篇 信息技术
- 5,180 篇 信息交换
- 5,169 篇 定义
- 3,492 篇 信息交流
- 3,405 篇 信息处理
- 3,140 篇 数据传送
- 2,842 篇 数据采集
- 2,195 篇 数据处理系统
- 2,184 篇 数据传输
- 1,993 篇 开放系统互连
- 1,900 篇 计算机
- 1,877 篇 规范(验收)
- 1,679 篇 数据交换
- 1,305 篇 规范
- 1,273 篇 编码
- 1,170 篇 电气工程
- 1,065 篇 电路网络
- 1,058 篇 接口(数据处理)
- 987 篇 网络互连
机构
- 2,350 篇 bsi
- 1,216 篇 iso/iec jtc 1
- 1,004 篇 ansi
- 555 篇 中国科学院大学
- 531 篇 ieee
- 399 篇 中国地质大学
- 362 篇 东南大学
- 340 篇 武汉大学
- 314 篇 华中科技大学
- 269 篇 电子科技大学
- 247 篇 iso/iec/jtc 1
- 241 篇 吉林大学
- 224 篇 iso/iec jtc 1/sc...
- 223 篇 同济大学
- 209 篇 天津大学
- 207 篇 大连理工大学
- 206 篇 长安大学
- 200 篇 北京交通大学
- 193 篇 哈尔滨工业大学
- 180 篇 清华大学
专题定制
- GNSS数据处理中IGS站的分布及数量的影响分析
- 浙江省国土勘测规划有限公司 浙江杭州310000杭州市勘测设计研究院有限公司 浙江杭州310000
- 来源 详细信息
- Evaluation of Forward Models for GNSS Radio Occultation Data Processing and Assimilation
- Chinese Acad Sci NSSC CAS Natl Space Sci Ctr Beijing 100190 Peoples R ChinaBeijing Key Lab Space Environm Explorat Beijing 100190 Peoples R ChinaChinese Acad Sci Key Lab Sci & Technol Space Environm Situat Aware Beijing 100190 Peoples R ChinaJoint Lab Occultat Atmosphere & Climate JLOAC NSS Beijing 100190 Peoples R ChinaUniv Chinese Acad Sci Sch Astron & Space Sci Beijing 100049 Peoples R China
-
来源
MultidisciplinaryDig...
 详细信息
详细信息
- A comparison of different regression models for the quantitative analysis of the combined effect of P2Y12 and P2Y1 receptor antagonists??????? on ADP-induced platelet activation
- Med Univ Lodz Dept Haemostasis & Haemostat Disorders Lodz PolandUniv Lodz Dept Demog Lodz Poland
-
来源
 ScienceDirect Journa...
详细信息
ScienceDirect Journa...
详细信息
- Strong Data Processing Constant Is Achieved by Binary Inputs
- Hebrew Univ Jerusalem Sch Comp Sci & Engn IL-91904 Jerusalem IsraelMIT Dept Elect Engn & Comp Sci Cambridge MA 02139 USA
- 来源 详细信息
- Structure, function, and evolution of plant ADP-glucose pyrophosphorylase
- Univ Nacl Litoral Fac Bioquim & Ciencias Biol Inst Agrobiotecnol Litoral Consejo Nacl Invest Cient & Tecn Santa Fe ArgentinaLoyola Univ Chicago Dept Chem & Biochem Chicago IL 60660 USA
- 来源 详细信息
- Advanced Computing Methods for Impedance Plethysmography Data Processing
- Opole Univ Technol Fac Elect Engn Automat Control & Informat PL-45758 Opole PolandLviv Polytech Natl Univ Inst Comp Technol Automat & Metrol UA-79000 Lvov Ukraine
-
来源
MEDLINE期刊
MultidisciplinaryDig...
PubMed
详细信息
- Query Optimization for Distributed Spatio-Temporal Sensing Data Processing
- Nanjing Univ Aeronut & Astronaut Coll Comp Sci & Technol Nanjing 211106 Peoples R ChinaNanjing Univ State Key Lab Novel Software Technol Nanjing 210023 Peoples R ChinaNanjing Univ Aeronut & Astronaut Coll Civil Aviat Nanjing 211106 Peoples R China
-
来源
PubMed
MultidisciplinaryDig...
MEDLINE期刊
详细信息

